This article is a guide to setup a Hadoop cluster. The cluster runs on local CentOS virtual machines using Virtualbox. I use this to have a local environment for development and testing.
I followed many of the steps Austin Ouyang laid out in the blog post here. Hopefully, next I can document using moving these virtual machines to another cloud provider.
Prerequisites
It assumes you are using the following software versions.
- MacOS 10.11.3
- Vagrant 1.8.5
- Java 1.8.0 (Using JRE is fine, use the JDK to run MapReduce examples later)
- Hadoop 2.7.3
Here are the steps I used:
-
First, create a workspace.
mkdir -p ~/vagrant_boxes/hadoop
cd ~/vagrant_boxes/hadoop
-
Next, create a new vagrant box. I’m using a minimal CentOS vagrant box.
vagrant box add “CentOS 6.5 x86_64” https://github.com/2creatives/vagrant-centos/releases/download/v6.5.3/centos65-x86_64-20140116.box
-
We are going to create a vagrant box with the packages we need. So, first we initialize the vagrant box.
vagrant init -m “CentOS 6.5 x86_64” hadoop_base
-
Next, change the Vagrantfile to the following:
Vagrant.configure(2) do |config| config.vm.box = "CentOS 6.5 x86_64" config.vm.box_url = "hadoop_base" config.ssh.insert_key = false end
-
Now, install Hadoop and it’s dependencies.
vagrant up
vagrant ssh
sudo yum install java-1.8.0-openjdk-devel
sudo yum install wget
wget http://apache.claz.org/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz ~
gunzip -c *gz | tar xvf –
-
Open up your ~/.bash_profile and append the following lines.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk.x86_64 export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=~/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
-
Source the profile.
source ~/.bash_profile
-
In /etc/hosts, add the following lines:
192.168.50.21 namenode.example.com 192.168.50.22 datanode1.example.com 192.168.50.23 datanode2.example.com 192.168.50.24 datanode3.example.com 192.168.50.25 datanode4.example.com
-
In $HADOOP_CONF_DIR/hadoop-env.sh, replace the ${JAVA_HOME} variable.
# The java implementation to use. export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk.x86_64
-
Edit the $HADOOP_CONF_DIR/core-site.xml file to have the following XML:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://namenode.example.com:9000</value> </property> </configuration> -
Edit the $HADOOP_CONF_DIR/yarn-site.xml file to have the following XML:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>namenode.example.com</value> </property> </configuration> -
Now, copy the mapred-site.xml file from a template.
cp $HADOOP_CONF_DIR/mapred-site.xml.template $HADOOP_CONF_DIR/mapred-site.xml
-
Edit the $HADOOP_CONF_DIR/mapred-site.xml to have the following XML:
<configuration> <property> <name>mapreduce.jobtracker.address</name> <value>namenode.example.com:54311</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
Edit the $HADOOP_CONF_DIR/hdfs-site.xml file to have the following XML:
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/hdfs/datanode</value> </property> </configuration> -
Make the data directories.
sudo mkdir -p /data/hadoop/hdfs/namenode
sudo mkdir -p /data/hadoop/hdfs/datanode
sudo chown -R vagrant:vagrant /data/hadoop
-
In $HADOOP_CONF_DIR/masters, add the following line:
namenode.example.com
-
In $HADOOP_CONF_DIR/slaves, add the following lines:
datanode1.example.com datanode2.example.com datanode3.example.com datanode4.example.com
-
Create a ~/.ssh/config file to avoid host key checking for SSH. Since these are DEV servers, this is ok. Note that the indentation here before StrictHostKeyChecking must be a tab.
Host * StrictHostKeyChecking no -
Now run these commands to finish the password-less authentication.
chmod 600 ~/.ssh/config
sudo hostname namenode.example.com
ssh-keygen -f ~/.ssh/id_rsa -t rsa -P “”
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
-
Exit the SSH session and copy the VM for the other hadoop nodes.
exit
vagrant halt
vagrant package
vagrant box add hadoop ~/vagrant_boxes/hadoop/package.box
-
Edit the Vagrantfile to look like the following below. This will create 5 Hadoop nodes for us using the new Hadoop VM.
Vagrant.configure("2") do |config| config.vm.define "hadoop-namenode" do |node| node.vm.box = "hadoop" node.vm.box_url = "namenode.example.com" node.vm.hostname = "namenode.example.com" node.vm.network :private_network, ip: "192.168.50.21" node.ssh.insert_key = false # Start Hadoop node.vm.provision "shell", inline: "hdfs namenode -format -force", privileged: false node.vm.provision "shell", inline: "~/hadoop-2.7.3/sbin/start-dfs.sh", privileged: false node.vm.provision "shell", inline: "~/hadoop-2.7.3/sbin/start-yarn.sh", privileged: false node.vm.provision "shell", inline: "~/hadoop-2.7.3/sbin/mr-jobhistory-daemon.sh start historyserver", privileged: false end (1..4).each do |i| config.vm.define "hadoop-datanode#{i}" do |node| node.vm.box = "hadoop" node.vm.box_url = "datanode#{i}.example.com" node.vm.hostname = "datanode#{i}.example.com" node.vm.network :private_network, ip: "192.168.50.2#{i+1}" node.ssh.insert_key = false end end end -
Bring the new Vagrant VMs up.
vagrant up –no-provision
-
Start Hadoop up on the namenode.
vagrant provision
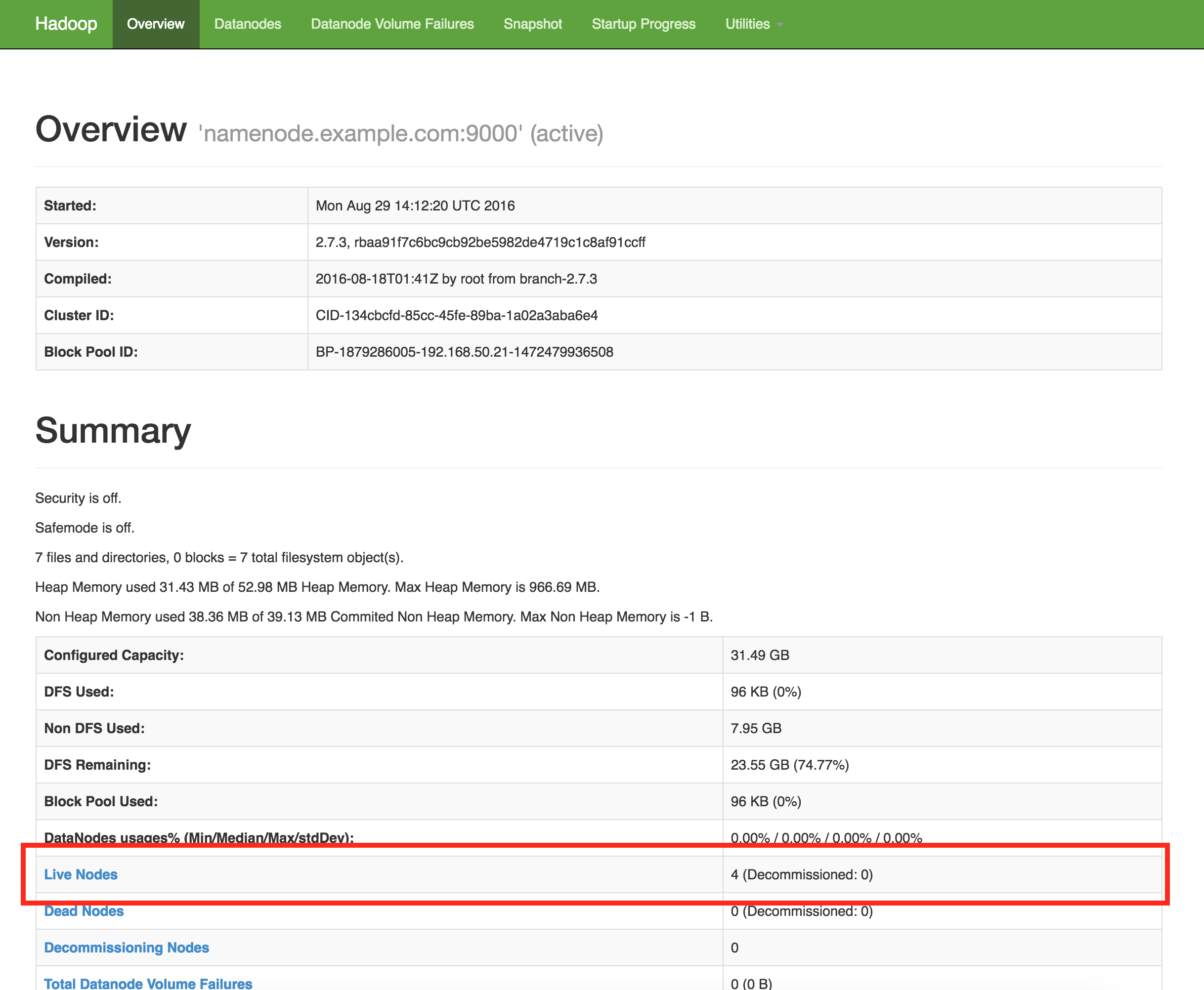
To test to see if the Hadoop is working, you can do the following.
First, from you local machine, you should be able to access the Web UI (http://192.168.50.21:50070/). You should see 3 live nodes running. Follow the MapReduce Tutorial to test your cluster further.